
tg-me.com/knowledge_accumulator/50
Last Update:
A Generalist Agent (Gato) [2022] - путь к AGI или тупик?
На мой взгляд, проблема требуемого количества данных в RL не может быть решена только улучшением алгоритмов.
Человек учится избегать отрицательных наград, не получив ни разу такую награду (например, нам не нужно упасть на машине в обрыв, чтобы понять, что это плохая стратегия вождения). Это происходит благодаря обобщению опыта из прошлого, полученного при решении совершенно других задач.
Deepmind в данной работе делает систему, которая аккумулирует опыт из большого количества задач - они учат единый трансформер под названием Gato копировать поведение экспертов в >500 различных задач в области RL, включая игры, управление роботом и т.д.
Сработала ли магия? К сожалению, не совсем.
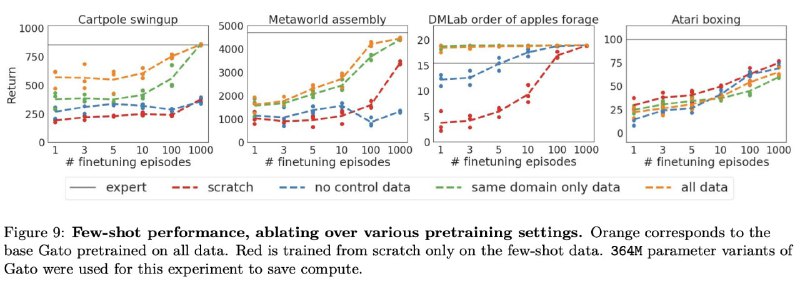
На картинке вы можете увидеть графики из ablation studies о том, насколько хорошо помогает в обучении на конкретной задаче предобучение на других задачах.
Имеет смысл смотреть на худший случай - Atari Boxing, в котором модель со случайном инициализацией обучается лучше предобученного Gato.
Это показывает, что обобщающей способности такого подхода не хватает, чтобы учиться быстрее на достаточно простой, но не похожей задаче.
Думаю, что мы нуждаемся в другом способе извлечения знаний из данных, если хотим добиться out-of-the-distribution обобщения, способностью к которому обладаем мы с вами.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/50